[멋쟁이사자처럼 부트캠프 그로스 마케팅] 데이터 분석 개론 : Pandas - SQL 연동
학습 목표
- ALTER TABLE 명령으로 테이블 구조 변경하기
- Python과 SQL 연동하기
1. ALTER TABLE
1) 열 추가 (ADD COLUMN)

2) 열 삭제 (DROP COLUMN)

3) 열 이름 변경 (CHANGE COLUMN)

4) 열 데이터 타입 변경 (MODIFY COLUMN)

5) 기본 키 변경 (ADD/DROP PRIMARY KEY)
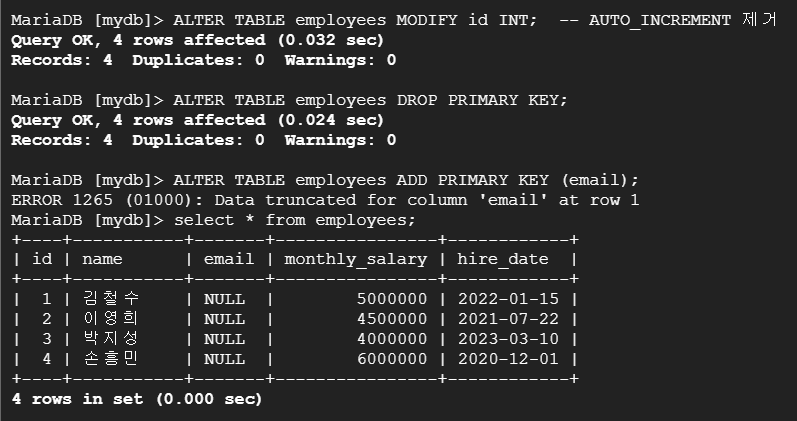
6) 테이블 이름 변경 (RENAME TO)

7) 인덱스 추가 및 삭제 (ADD/DROP INDEX)
ALTER TABLE staff ADD INDEX idx_name (name); -- 인덱스 추가
ALTER TABLE staff DROP INDEX idx_name; -- 인덱스 삭제INDEX -- 자주 검색하는 컬럼에 검색 속도를 빠르게 할 수 있도록 함
8) 유니크(UNIQUE) 제약 조건 추가
ALTER TABLE company_data ADD CONSTRAINT unique_emp_name UNIQUE (emp_name);UNIQUE -- 중복된 값이 들어가지 못하도록 제한
9) CHECK 제약 조건 추가
ALTER TABLE company_data ADD CONSTRAINT check_salary CHECK (monthly_salary >= 3000000);CHECK -- 컬럼에 저장될 값이 특정 조건을 만족해야 하도록 제한
2. Python - SQL 연동
[Step 1] SSH 터미널 : Maria DB 초기 설정
-- change directory
cd / -- 루트 디렉토리(최상위)
cd var
-- make directory
sudo mkdir gm-lab3 -- SuperUser DO (관리자 권한 실행)
sudo chmod -R 777 gm-lab3 -- 디렉토리의 owner, group, others에게 r, w, x 권한 부여
cd gm-lab3
-- Maria DB 설치
sudo apt update && sudo apt upgrade
sudo apt-get install mariadb-server
-- MariaDB(Mysql) 데이터베이스 생성
sudo mysql –u root –p
-- 엔터
CREATE DATABASE backend default CHARACTER SET UTF8;
show databases;
use backend;
-- user 생성
GRANT ALL PRIVILEGES ON backend.* TO [아이디]@localhost IDENTIFIED BY '비밀번호';
-- exit하고 로그인 --
-- 파이썬 설치
sudo apt-get update
sudo apt-get install python3-pip
-- 라이브러리 설치
pip install mysql-connector-python pandas
sudo chmod -R 777
이 새끼가 날 힘들게 함
저거 한 줄 빼먹었더니 영원히 날 권한 없다고 꺼지라 함
* 7 = 4 (읽기) + 2 (쓰기) + 1 (실행) / 755 = 소유자는 모두 권한, 다른 사람은 읽기와 실행만 가능. 이런 식
[Step 2] 연동할 py 파일 생성
import mysql.connector
import pandas as pd
# 1. MariaDB 연결 설정
db_config = {
"host": "localhost", # MariaDB 서버 주소
"user": "아이디", # 사용자 이름
"password": "1234", # 비밀번호
"database": "backend" # 사용할 데이터베이스
}
# MariaDB 연결
conn = mysql.connector.connect(**db_config)
cursor = conn.cursor()
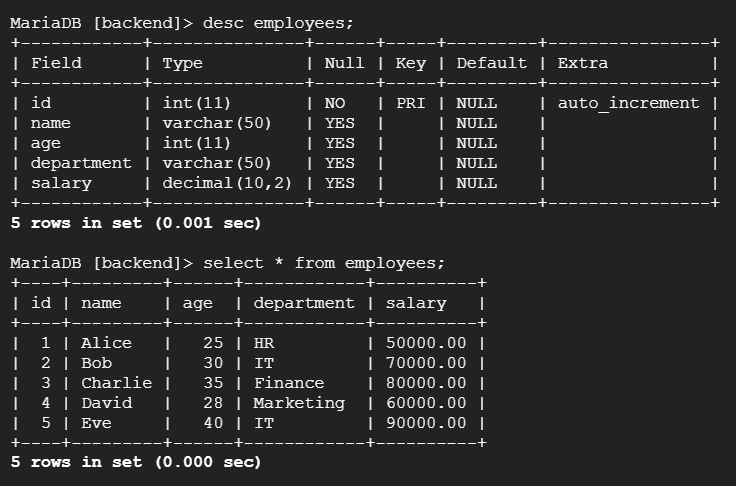
# 2. 테이블 생성
cursor.execute("DROP TABLE IF EXISTS employees;") # 이미 존재하면 삭제 후 생성
cursor.execute("""
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
age INT,
department VARCHAR(50),
salary DECIMAL(10,2)
);
""")
# 3. 샘플 데이터 생성 (pandas DataFrame 활용)
data = {
"name": ["Alice", "Bob", "Charlie", "David", "Eve"],
"age": [25, 30, 35, 28, 40],
"department": ["HR", "IT", "Finance", "Marketing", "IT"],
"salary": [50000, 70000, 80000, 60000, 90000]
}
df = pd.DataFrame(data)
# 4. 데이터 삽입
insert_query = "INSERT INTO employees (name, age, department, salary) VALUES (%s, %s, %s, %s)"
values = [tuple(row) for row in df.to_numpy()]
cursor.executemany(insert_query, values)
conn.commit()
print("데이터 삽입 완료")
# 5. 데이터 조회 및 pandas DataFrame으로 변환
cursor.execute("SELECT * FROM employees")
rows = cursor.fetchall()
# 컬럼명 가져오기
column_names = [desc[0] for desc in cursor.description]
df_result = pd.DataFrame(rows, columns=column_names)
# 6. 결과 출력 (pandas 기본 출력 방식 사용)
print("\n=== Employees Table Data ===")
print(df_result.to_string(index=False)) # 인덱스 없이 출력
# CSV로 저장 (필요한 경우)
df_result.to_csv("employees_data.csv", index=False, encoding="utf-8")
print("데이터를 'employees_data.csv' 파일로 저장하였습니다.")
# 연결 종료
cursor.close()
conn.close()
[Step3] FileZilla : py 파일을 디렉토리에 업로드


[Step 4] 터널에서 py 스크립트 실행

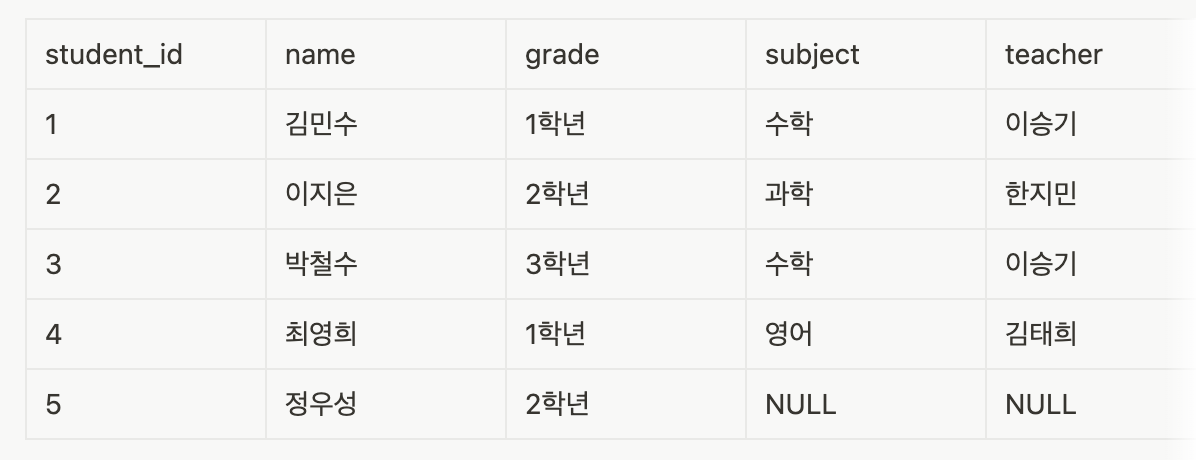
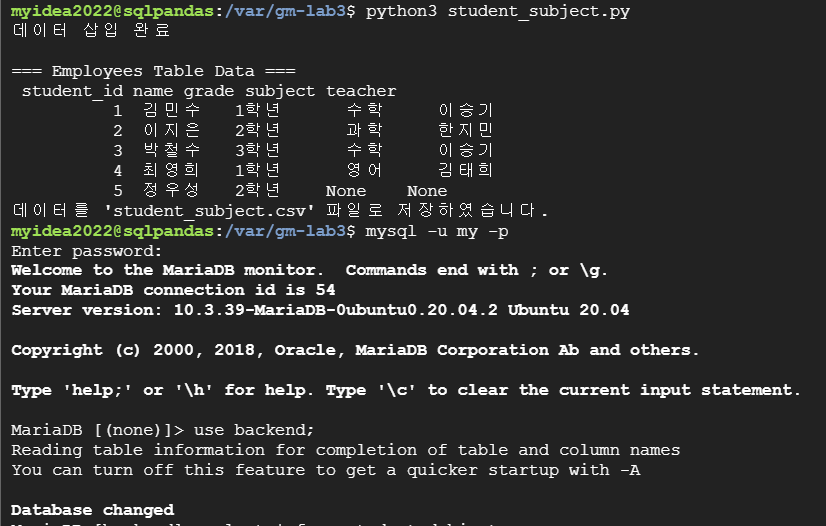
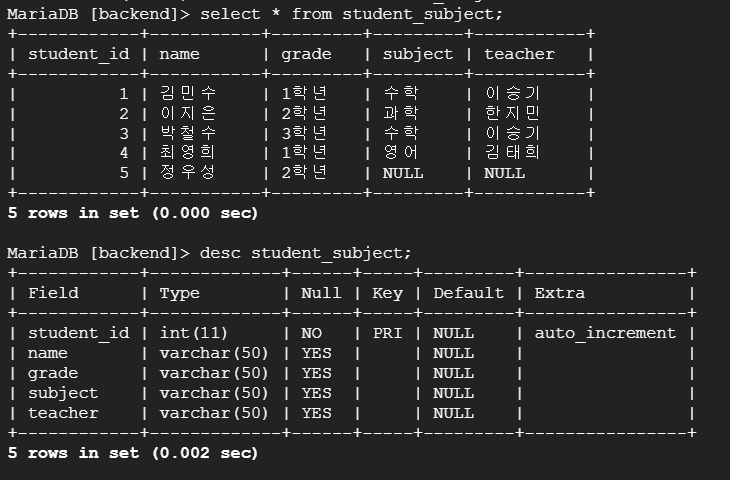
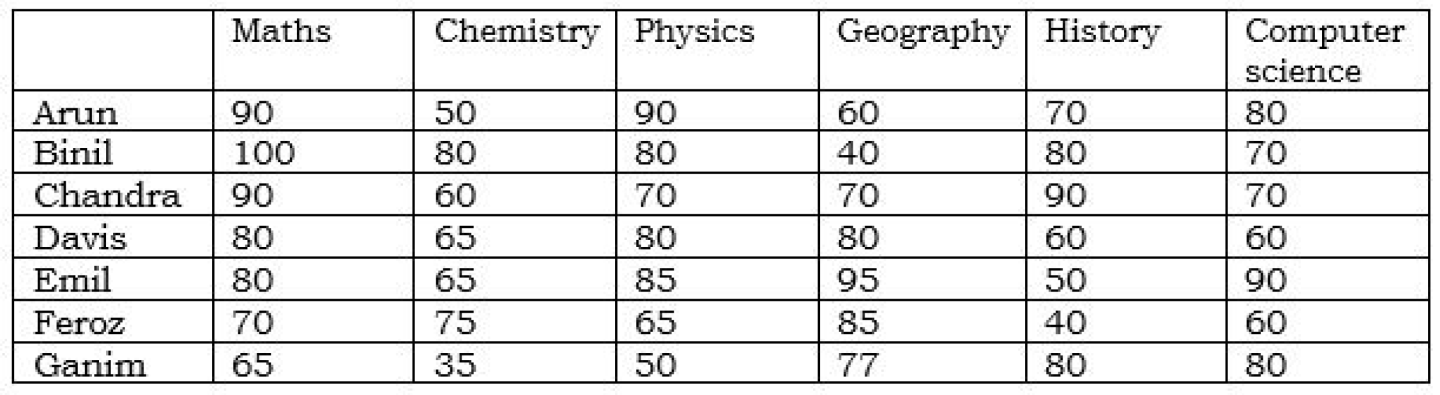
연습 문제
: 제시된 표를 py 파일로 생성해 MariaDB에 업로드하기
# 1.
#2.


블로그 챌린지는 그날 배운 내용을 정리하되 밀린 복습은 주말을 활용하기루 함 이게 당연?할 지도? ;;
이제 프렌즈 아이드롭 쿨하이 사러갈게요,,